Here in the Open Source Cloud Engineering (OSCE) division of Capgemini Custom Software Development, cloud native development is what we do. What we struggle with is explaining to people exactly what that is. Cloud native is a buzzword which is thrown around a lot, but what does it mean for a team of developers and how does it help their clients?
What is cloud native?
As a company hosting bespoke or “COTS” software, simply moving that software to servers hosted by a cloud provider is not necessarily going to be the most cost-effective solution. Cloud-hosted servers are usually more expensive, because the cost accounts for the engineering teams who install and manage the hardware and the software teams who manage the apps allowing you access. Cloud vendors will offer different cost incentives to their clients to use their hardware and software offerings in a manner which is beneficial to the vendors. For example, if you want an entire dedicated Linux server with 2 sockets and 48 physical cores, but you’re not using it all day / every day then it’s a wasted resource for the cloud vendor. If you agree to let the vendor use the server when you’re not using it and add extra peripherals to it, and the vendor can then charge another client for that processing power, it’s more efficient. There’s a lot of creative billing in this space - for instance AWS Spot Instances, where you effectively bid for processing power that holds different values at different times based on demand.
To us, cloud native applications are those which are written for maximum efficiency when deployed with a specific cloud provider. In this sense, by “efficiency” I mean cost efficiency, what is the lowest cost for running your application logic in a stable and scaleable way - but under the covers that probably implies maximum processing efficiency too. We also consider efficiency in the development pipeline - do you have test environments sitting there racking up costs when you aren’t using them? What about the servers where your pipeline code runs, do you tear that down when not in use? All these considerations tie into cloud native development.
By this definition, the ultimate cloud native application is a function-as-a-service, or “serverless”, and indeed if you are starting a new project or adding peripheral functionality to an existing architecture, you should consider function-as-a-service first as potentially the cheapest and least time-to-market for your functionality. There are reasons why you wouldn’t choose function-as-a-service, which I will go into shortly, the most commonly stated of which is that you don’t want your business logic to only run on one cloud provider. You may wish to run it on-premise too, you may not want to re-architect to a specific provider’s serverless solution framework/languages, you may be wary of vendor lock-in. And of course a serverless function is just that - a single function that must be orchestrated and its inputs and outputs must be managed, so it’s not a full application in itself.
There is also an argument that containers are kind of serverless depending on how they’re deployed - OK technically the thing in your container may have a lot of server-ish features, but you don’t really care about how they run when you hand them over to a platform such as Google’s GKE, Azure AKS, or Amazon’s EKS So where does that leave our definition? How about:
Cloud native applications are written for maximum efficiency when deployed to the cloud, whilst remaining flexible and portable
It’s starting to get a bit long isn’t it!
What is Capgemini’s cloud native offering?
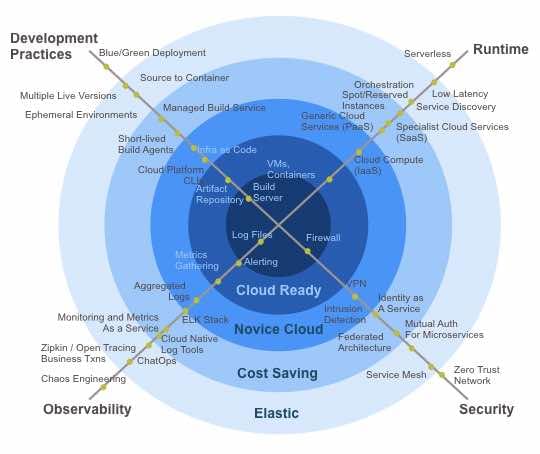
OK here’s the sales pitch - but we’re very proud of it. OSCE have a couple of offerings in the cloud native space. One is our Cloud Native Maturity Assessment, which helps companies to judge where they are on the route to maximising cloud efficiency, and the other is our default, open-source cloud native development platform.
Cloud Native Maturity Assessments
Many aspects of cloud development are overlooked when people think about moving their estates to the cloud. Here are our Ten Steps to checking whether your business is getting the most out of moving to the cloud.
1. Build Server
Question One - how are you actually going to get your application out into your shiny new cloud space? You need to go back to basics and look at your delivery pipeline before you’re ready for the cloud. Once you relinquish control of your deployment environment, you have to make sure it is reproducible automatically at every step. A build server is a good place to start in automating your deployment process. You need to be repeatably creating and testing an immutable artifact that can be deployed onto your cloud platform. But where does that build server itself run? Can you stick that in the cloud too?
2. Internet-visible artifact repository
So your build server has built this great Docker image. Now what? How do you get it out to the cloud? Many companies will have complex firewalls to prevent exactly this sort of access, so you’ll need to start thinking about how to manage the process. Work from the principle of minimum access too, for instance your deployment pipeline only needs read access to your repository. And make sure every access is audited. If your artifact repository is itself in the cloud, you’ll need a separate set of credentials for your build server to access it and write to it - you need to start thinking about having key vaults to store these credentials and figuring out how to safely pass these around.
3. Patching Process
Before you throw your estate to the internet wolves, think of how you’re going to apply patches and fixes to it. There’s no longer a short-cut whereby you can log onto the machine and switch out a JAR file or something equally terrible, and you don’t want to have to bring down the whole cloud environment for an emergency change to one of your core Docker images. Think about your patching process now, and save a lot of pain tomorrow. On the plus side, running parallel environments and switching between them suddenly got a whole lot easier, so this is one of the best routes to take.
4. Microservice Architecture
Let’s think about this. Is it really a prerequisite of cloud native? I think so. Sure, if you had a “big ball of mud” type architecture you could simply rent a server big enough and host it in the cloud, but the cost savings from elasticity wouldn’t be there. If your architecture is deployed in a modular fashion and you can horizontally scale the pieces with the most load up and down as needed, there’s your saving.
5. Choose your abstraction level carefully
There are many layers of abstraction when moving applications from on-premise to the cloud. We’ve mentioned the simplest step of Infrastructure-as-a-Service, and the furthest step of serverless, but how do we decide where in between to draw the line? OSCE have chosen Kubernetes-as-a-service as our abstraction layer. We build and test immutable Docker containers, and deploy these to a cloud Kubernetes service. Why? Well - I put this question to our team and the following gems came back:
- Container Orchestration Just to point out, we need container orchestration software. The real advantage of microservices is that they are deployed separately - all this stuff about the code being modular is not new, even before object-orientation our functions “did one thing and did it well”. The separate deployment aspect means you can scale horizontally, you can restart failed instances, you can kill off long-running instances, manage IP addresses. You get reliability and efficiency - but you need to automate this process. And the market for automating container lifespans is narrow - Kubernetes is the clear choice.
- Speed to market People are familiar with setting up an environment where you can run Docker containers locally, and if that’s your deployment unit it’s fast to transfer it to your cloud Kubernetes environments. You can run pretty much anything in a Docker image, but if you want your old Cobalt code to be serverless you’ll have to rewrite it in another language.
- Empowerment of Developers It’s not too bad for developers to manage Docker containers. There’s a familiar language for defining the container, it’s OS concepts that we know, there are a lot of templates to get started with. Kubernetes is another matter - more networking skills are required to configure a Kubernetes cluster that devs may not have. It fits nicely with the desire for a developer to be self-sufficient; “Build apps, not platforms”. (thanks Kevin Rudland for that one)
- Considerable cost savings Kubernetes managed services have bonuses such as you don’t need to run your own Kubernetes master nodes, the service includes this, so you just pay for your workers. And enough of the underlying infrastructure is obfuscated from you to allow cloud vendors to provide efficient platforms.
The slight down-side of Kubernetes-as-a-Service is that you may feel locked in to the specific Kubernetes service provider - you can limit this lock-in by sticking to core Kubernetes where possible so that moving isn’t too difficult. Or, to steal another direct quote from the team, “avoiding lock-in for its own sake is counter-productive. You’re left choosing from lowest common denominator services and lose all the benefits of new, extremely useful offerings. Porting from one provider to another very rarely happens, but wishing you could use a few of the dozens of great vendor proprietary services happens regularly”. There is Google’s open-source interim layer, KNative, which our team roundly embrace. KNative runs on Kubernetes and allows you to seamlessly build and deploy Docker containers to Kubernetes without knowing where the underlying Kubernetes pods actually are - are they in cloud A, cloud B or on-premise or on my dev machine? Doesn’t matter!
6. Aggregated Logging
Application supportability in the Cloud is a really big jump. You can’t just log onto the box and get the output files from a process, or see what’s hanging. You need to think, in advance, of all the things that could go wrong and plan for how you would know they have gone wrong in the cloud. Fortunately the cloud providers help a lot, with some really great logging APIs available, but you have to architect to ensure you are using them correctly. A good first step is to choose an internet-accessible log repository, set up a secure way to read and write to it, and send ALL your logs there. You’ll also need a robust framework for creating correlation IDs so that you can trace function calls between services. Then you can look into the cloud-native offerings of your chosen platform and see where savings can be made.
7. Infrastructure as Code
Wait, what? I thought we got rid of the infrastructure? Well, yes you did, but you still want to control and define your environment. This is where apps like Terraform and Helm come into play. You can define your cloud-provider-specific infrastructure definition, and spin it up and take it down again whenever you like - including your tooling platforms.
8. Vulnerability Scans
There is an implicit number 0 on this list - security. As soon as you’re outside your business LAN, on the internet, you’re instantly at risk of attack. Vulnerability scans and intrusion detection software are suddenly vital, and should be run as part of your build pipeline. As a first level you can install and run software such as Snyk yourself, either on-premise or in the cloud, but for cost-saving consider moving to the as-a-service model.
9. Ephemeral Environments
I love this term. Really what it means is, now that you’ve got your infra-as-code in place, you can go around ripping things down with gay abandon whenever they’re not being used, in complete confidence that you can spin them up again whenever needed. This is great for things like the build pipeline, where you will have an awful lot of software that runs and uses a lot of processing power, but only occasionally. Great for UAT, load testing, integration testing too. We love ephemeral!
10. Low Latency
Now that we’re flying in the cloud, we can start to get into the details of really maximising performance. Why bother with the overhead of HTTP between microservices? And do we need JSON - maybe we can switch to binary APIs between layers? Now that we are cloud native, we can start to focus on really streamlining our architecture. Spread those wings!
Why not serverless?
I mentioned at the start that I’d talk about why the Open Source Cloud Engineering team choose not to head in at the serverless level of abstraction for our default cloud native architecture, even for a greenfield project. The main reason is that we are looking at the big picture, and a serverless function is not an architecture in itself. For a start, think about state. Serverless functions are stateless, yet to be modular we must have multiple functions interacting together and managing data between themselves. So we already need some kind of framework to co-ordinate function calls and parameters - we probably need some kind of queue or event stream, and some kind of data store, and some complex rules to manage when each function is triggered based on which data or event.
You might have to significantly adapt your architecture to incorporate all serverless functions, and you’re at risk of losing the purpose of that architecture in the process. There are frameworks to manage state between serverless functions, such as AWS step functions, and you can read about our experiences with the Serverless Framework, although they are usually very cloud-vendor-specific. There are very specific constraints around serverless functions too - such as a fixed runtime of n seconds per execution, only certain languages supported which may not match the skillsets of your development teams, and quite a steep learning curve for configuration. For instance, who here knew that by default an AWS lambda function will retry 10,000 times under certain failure conditions?! Lambda architectures are still quite bleeding edge and interesting problems such as this can come and bite you when you’re least expecting it.
There is also the very rational fear that businesses have of being tied to a single cloud provider. There is the concern that the vendor may cease to operate, or dramatically change its cost model. Conversely, what if my application deployment process is based around using AWS Elastic Beanstalk, and I suddenly discover that Amazon are in fact my company’s biggest competitor? How can you trust Amazon not to gain insight from the architectures and applications you’re deploying? You can imagine how often that continues to happen in the modern business landscape! Companies want to maintain a certain level of control and autonomy over their applications and are often uncomfortable about close ties to a specific cloud vendor. Despite all this, Serverless functions can always be considered first, particularly for small new tasks that “hang off” your main architecture, and a recent DataDog survey suggests that this is exactly what people do. The user group with the highest take-up of serverless is companies that deploy containers, so if they already have the containers, I’m guessing that the serverless functions themselves are peripheral functionality - helping to log/manage/alert/monitor the main application which runs on the containers.
The “cold-start” problem is often cited as an issue with serverless functions but I do feel we are able to solve this now. The gist of the problem is that in an efficient architecture, the function’s runtime environment is only spun up when it’s needed and is then destroyed, and especially for languages like Java with a JVM to launch this spin-up can be noticeably slow. Common workarounds include reducing the minimum number of functions running, so you are more likely to have one function up and running if it’s handling the majority of requests. Or pay a tiny bit more and have one instance staying “hot” for longer periods to take initial load while the others spin up. Also making sure you pick the right language for the job helps - it’s much faster to spin up a Node runtime than Java, for example, although check out our earlier post for more information on how to decrease your Java application footprint.
So in summary, containers are cloud-native and can effectively be serverless deployments and for now, we’re happy with that. Consider function-as-a-service but with an open mind. In the words of Bret McGowen when he spoke at Serverless Days Cardiff, our clients want “Portability using industry standards and open source”. And whether you’re developing from scratch or moving an existing architecture, containerised applications deployed to Kubernetes-as-a-service gives you just that, fast.
