I’ve said before that using the cloud feels to a certain age of developer like a kid in a sweet shop. Talking to a colleague of a similar age recently about how he wrote his own message bus in C, we agreed the current generation don’t know how lucky they are to use this software as a service via few clicks on a beautifully laid out portal! This week I was amazed again what can be done in a few clicks, whilst taking part in a Capgemini hackathon. The brief was short and open – “build an app with AI”, and the toolset was $300 credit on the Microsoft Azure portal.
What my team decided to build was a RAG – a retrieval-augmented generative AI solution. We have an email group that’s many, many years old and contains a lot of company knowledge from people who have long-ago retired, so we decided for our solution to “resurrect” them by using the mailbox files as a data source for our RAG. We based our solution on this Azure sample application, and architected as below:
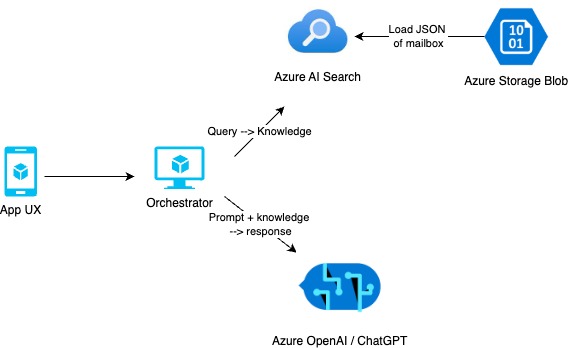
For a bit of fun, we also used Gen AI (Microsoft Copilot) to write our hackathon presentation – given a description of the architecture it came up with this masterpiece, which I kind of like:
Data source
First step was to get the mailbox file into JSON format so it could be uploaded to the Azure portal. Next we had to learn about “vectorisation”.
Many of us are starting to become familiar with vector datastores and huge numbers of vectors being quoted – for example the “ada 2” embedding engine that we used produces vectors with 1,536 dimensions. I always describe vector dimensions as “ways to represent the word cat”, for example with one dimension a cat is a cute but annoying furry animal; with 1,536 dimensions it can also be a cat o’ nine tails; a shortcut for concatenation; any subspecies of the genus Felis; a play; a musical; the arch-enemy of a dog; a cartoon… OK I won’t list 1,536.
It turned out to be pretty easy to vectorise our data. We stored it in an Azure storage blob so the cloud could be granted read permissions on it, we spun up an OpenAI instance and deployed our “ada 2” embedding model in it, we created an Azure AI search index (one of my favourite Azure products) and chose “load and vectorise data.” This wizard allowed us to specify our data source and our embedder, and then it went off and did some magic, and then we had vectorised data! As a test, I searched the AI Search index for the term “BBC”. I knew it wasn’t in the data source, but I knew there was a long debate in the data source about a Fawlty Towers TV series, and sure enough the vector returned, with a suitable degree of confidence, the email chain in question. Fantastic.
What is the process carried out by the embedder? Well, it turns the words into numbers, based on how it has been trained, and there are calculations that can be performed on these numbers to figure out how “semantically similar” two words are – so for example in English the vectors for the words “coder” and “developer” should have very similar outputs from the calculation. When I look in my AI search index post-vectorization, I can see my initial data broken down into chunks, and I can also see arrays of arrays of numbers for each chunk. There are different embedding models you can use to vectorise your data, which have been trained on different data sets to vectorise words – here, specialisms can come in such as a data set of medical terms that would have been trained to recognise how they link together. The language of the text is also presumably a very important factor in training the embedder! We now already have a very powerful machine-learning-augmented search on our data, all we really need to do is add an interface to it. As this is an AI hackathon, we’ll add a natural-language chatbot interface.
Chatbot Interface
You can query the OpenAI instance that we’ve spun up for our hackathon in natural language by installing a “chat module” that will do this automatically, but that will ask the LLM, which I guess has been trained on a huge amount of internet data, directly – and that’s not what we want. For a RAG, we want to restrict the queries to a data set that we know contains the answer we want for our domain. So we build an “orchestrator” application to set in between the user and OpenAI, intercept queries and then use prompts to force the LLM, with extreme prejudice (and maybe some bribes) to only use the data we want and only reply in the way we expect.
Our user interface is a simple one-page application with a chat box you can type into and submit to our orchestrator layer. The first step for the orchestrator is to use OpenAI to translate the user’s question into a better search term for our AI search index. So when the user sits on the keyboard and writes a misspelt, badly phrased query like “wot r the main chacaraterts in that SOAP with John Cleese in it”, we can clean it up a bit before we search our vectorised data. OpenAI is good at this – it’ll return something like “Fawlty towers main characters” (although it does prefer to spell “Faulty” correctly!) So we build that API call first. The response, if there is any, is then fed into an API call to our AI Search index, which will return the data it has matched plus a probability score that the data is relevant. There’s scope here to filter based on probability score if we’re getting inaccurate responses. Then we take this data and craft another OpenAI call, this time to the chat endpoint. We provide the data we’ve received from AI search, and a strongly worded prompt along the lines of “You are a helpful assistant, you will return a paragraph and bullet points of relevant data, you will ONLY use the provided data to generate your answer, if you cannot find the answer in the provided data then say ‘I don’t know’” and so on. Despite training courses telling you otherwise, prompt engineering is a bit of a dark art, so you may need to experiment with the prompt a bit to get better results.
The response from this query should be in natural language and contain answers only from your data set, so it can be directed straight back to the user, and voila! Your very own RAG application.
Cost Considerations
So what does it cost? From an Azure perspective, you need to host your static web front end and your orchestrator app – there are various ways to do this, you could use a Function App for the orchestrator and a “Static Web App” for your one-page front end, that might be the most cost-efficient.
You only need to deploy the OpenAI embedding module whilst you vectorise your data, but you do need the OpenAI chat interface which is charged per API call so that would be 2 calls per application use. You could skip the “translate-my-question” call if you really wanted to reduce this – although the pricing model does not give much benefit for this.
There is a handy in-portal calculator to help you figure out your OpenAI costs based on your created architecture in Azure, for my hackathon estate which included an OpenAI chat the estimate was $1,400 per month per PTU (this is based on using the chat feature 24 hours a day) and I’d apparently need 15 PTUs! Ouch. Lowering this to perhaps 7 hours a day for 20 working days is a slightly more acceptable $4,200 a month, but still – costs to be very wary of.
You need your AI search instance; this is charged per GB of data stored rather than per API call so the cost really depends on the size of your RAG data set.
Security Considerations
Whenever you use Software as a Service, you need to be aware of what you are sending to the vendor and what they are contractually able to do with it. In this case, our AI search data is contractually secure in the index, but we also need to look at the contract for the OpenAI calls – for example, is Microsoft allowed to keep a copy of our query data? There’s a terms of service page to help you understand with lots of promises on things Microsoft won’t do, but whether this is acceptable will be very specific to your use case requirements so get your reading glasses on.
Then, as for any cloud architecture, you want to be sure that each component has the minimum viable permissions to access each other component and that your internet-exposed APIs and websites are protected by login. For this architecture, we could make the Azure storage blob read-only, give the Azure OpenAI instance contributor permissions to the AI search service, and give the orchestrator service read permissions to the AI search and query permissions to the OpenAI chatbot.
Conclusion
It was pleasingly straightforward to create this RAG, although I am not certain that the cost of adding the chatbot front end significantly increases the value of the product; perhaps just the vectorised data is enough to increase the usefulness of a data source by making it contextually searchable? I think I did succeed quite well in resurrecting all those retired employees though. All their conversations about Fawlty Towers and the value of the Capgemini car lease scheme have been brought back to life in a very convincing and accessible way!
