Introduction
Redis (REmote DIctionary Server) is an open source in-memory data structures server. Similarly to key-value stores, like Memcached, data on Redis is held in key-value pairs. Differently though, while in key-value stores both the key and the value are strings, in Redis the key can be any binary sequence, like a string, but also a digest (e.g. the output of a SHA-2 function) and the value can be of different types, among them:
- Lists, e.g.:
key = "shapes"
value = ["square", "triangle", "triangle"] # duplicates allowed
- Sets, e.g.:
key = "shapes"
value = ["square", "triangle"]
- Hashes, e.g.:
key = "shapes"
value =
{
"name": "square",
"sides": 4
}
- Bit arrays/bitmaps, e.g.:
10000001010010 # up to 2^32 different bits
Because values are typed, Redis is capable of manipulating the content accordingly, e.g.: prepending or appending new elements to a list, computing the intersection between two sets, replacing single elements in a hash, etc.
Azure Cache for Redis is a managed in-memory data store service, based on Redis, offered by Microsoft Azure.
I have recently had the opportunity to work on an enterprise software system, featuring a traditional 3-tier architecture, fully hosted in Azure, made of the following components:
- web and mobile application clients
- mid-tier backed by a Node.js application, leveraging the Express framework and Azure Mobile Apps SDK
- data layer, backed by a General Purpose, Gen5, 2 vCores Azure SQL database
Despite the optimisations performed on tables and queries, the latency of client calls hitting a few specific tables was still considered too high. Hence, adopting the cache-aside pattern leveraging Azure Cache for Redis was explored as a possible solution and the original vs. new behaviour profiled.
Creating the cache in Azure
Setting up Redis in Azure is pretty straightforward, as detailed in the quickstart documentation. After completion, host name, ports, and access keys are available to be used by external applications for connection. The tier selected for the development and benchmarking configuration was Basic C0.
Changes to the mid-tier source code
The basic Azure Mobile Apps table controller is as per the samples on GitHub. To support Redis, the relevant npm package was added and the following changes were applied to the table controllers:
cache-service.js
var redis = require("redis");
var cacheConnection = module.exports = redis.createClient(process.env.REDISPORT, process.env.REDISCACHEHOSTNAME,
{auth_pass: process.env.REDISCACHEKEY, tls: {servername: process.env.REDISCACHEHOSTNAME}});
table.js
const cacheConnection = require('../cache-service.js');
var table = module.exports = require('azure-mobile-apps').table();
table.read(function (context) {
return new Promise( (resolve,reject) => {
let url = JSON.stringify(context.req.originalUrl);
cacheConnection.get(url, (err, cachedResults) => {
if (err) {
reject(err);
return;
}
if (cachedResults) {
resolve(JSON.parse(cachedResults));
} else {
context.execute().then(sqlResults => {
cacheConnection.setex(url, process.env.REDISCACHEEXPIRY, JSON.stringify(sqlResults));
resolve(sqlResults);
}).catch(error => {
console.error(error);
reject(err);
})
}
})
})
})
Upon request reception, the related path is serialised into a string, which is used as a key in Redis: the key is checked for existence in the cache and, in case of a hit, returned to the client. Otherwise, in case of a miss, the database is queried, the result returned to the client and the key-value pair inserted into the cache.
Benchmarking setup
The data held in the tables of interest exhibits a synchronous, low frequency update, which allows the setting of a long time to live for the related cache keys (6 hours).
To benchmark the solution including Redis vs. the original one, the keys/requests were extracted from the cache, close to the end of the expiration window, to maximise the representativeness of the sample. The requests were then utilised as input to the profiling Apache Benchmark (AB) tool, which issues requests against the given endpoints and reports on timings.
redis-cli
The tool used to extract the keys is the redis-cli. Given the limited support from the Azure Console, to run commands against the Redis service, a Redis Docker image was started locally and the relevant redis-cli commands were executed to connect to the remote cache and download the keys:
$ docker pull redis
$ docker run -d -p 6379:6379 --name redis1 redis
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
fabee04737a9 redis "docker-entrypoint.s…" About a minute ago Up About a minute 0.0.0.0:6379->6379/tcp redis1
$ echo "keys *" | redis-cli -h {server name}.redis.cache.windows.net -p 6379 -a {access key} > {file name}
Apache Benchmark
AB is the tool chosen for profiling the responsiveness of the server. It simulates a client behaviour by exercising a server’s HTTP endpoints. Between the most notable ones are:
- n : the number of requests
- c : the degree of parallelism (the number of multiple requests to perform at a time, the default is one)
The forecasted maximum number of concurrent users in the system under examination is 20.
A sample report looks like this:
Concurrency Level: 1
Time taken for tests: 14.522 seconds
Complete requests: 10
Failed requests: 0
Total transferred: 1241440 bytes
HTML transferred: 1231310 bytes
Requests per second: 0.69 [#/sec] (mean)
Time per request: 1452.156 [ms] (mean)
Time per request: 1452.156 [ms] (mean, across all concurrent requests)
Transfer rate: 83.49 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 140 164 29.6 161 244
Processing: 1109 1288 169.8 1280 1685
Waiting: 968 1154 167.7 1167 1538
Total: 1271 1452 175.7 1442 1851
Percentage of the requests served within a certain time (ms)
50% 1442
66% 1455
75% 1558
80% 1588
90% 1851
95% 1851
98% 1851
99% 1851
100% 1851 (longest request)
The script
Leveraging AB, for both the with/without Redis scenarios, a bash script was implemented to:
- retrieve the keys/urls
- loop through those
- target each one, running the AB command
- store the output in a file
- parse the output to extract the mean and standard deviation of the latency
#!/bin/bash
redis_keys_file= # the file listing the redis keys (urls/endpoints)
total_ab_requests= # total number of requests per url/endpoint
parallel_ab_requests= # number of requests to run in parallel
redis_server= # redis server
redis_port= # redis port
access_key= # access key
node_server= # node server
with_redis_table_name= # table name in case of solution with Redis
without_redis_table_name= # table name in case of solution without Redis
ab_output_with_redis='./ab_output_with_redis.txt'
chart_data_with_redis='./chart_data_with_redis.txt'
ab_output_without_redis='./ab_output_without_redis.txt'
chart_data_without_redis='./chart_data_without_redis.txt'
[ -e $ab_output_with_redis ] && rm $ab_output_with_redis
[ -e $ab_output_without_redis ] && rm $ab_output_without_redis
echo "keys *" | redis-cli -h ${redis_server}.redis.cache.windows.net -p $redis_port -a $access_key > $redis_keys_file
total_lines=$(wc -l < $redis_keys_file)
while read line; do
host="https://${node_server}.azurewebsites.net"
path_no_quotes=${line//\"/} # remove quotes
path_decoded_url=$(echo -e ${path_no_quotes//%/\\x}) # decode url
path=${path_decoded_url// /+} # replace spaces with '+'
path_without_redis=${path//$with_redis_table_name/$without_redis_table_name} # replace Redis endpoint with non-Redis endpoint, the backing database table remains the same in both cases
ab -n $total_ab_requests -c $parallel_ab_requests -H 'zumo-api-version: 2.0.0' $host$path >> $ab_output_with_redis
ab -n $total_ab_requests -c $parallel_ab_requests -H 'zumo-api-version: 2.0.0' $host$path_without_redis >> $ab_output_without_redis
done < $redis_keys_file
# extract mean and standard deviation figures for each iteration
output_files=( $ab_output_with_redis $chart_data_with_redis $ab_output_without_redis $chart_data_without_redis)
for index in 0 2;
do
output_figures="$(grep 'Total:' ${output_files[$index]})" # the line including mean and standard deviation
[ -e ${output_files[$index+1]} ] && rm ${output_files[$index+1]}
echo "mean sd url" > ${output_files[$index+1]} # heading
i=0
while IFS= read -r figure; do
figures_array=($figure) # split the figures
printf "%s %s %s\n" ${figures_array[2]} ${figures_array[3]} $i >> ${output_files[$index+1]} # append the figures + url index
((i++))
done <<< "$output_figures"
done
Test Results
The output of the previous step is a set of 2 files, representing the latency for the two solutions, with and without cache. The format of the files is as follows:
mean sd url
1452 175.7 0
1429 96.6 1
1541 287.6 2
1224 57.6 3
1241 153.0 4
...
Charting the results
Last, a small script in R plots, in the same graph, the data sourced from the two files:
library(ggplot2)
library(RColorBrewer)
# Load the data
withRedis <- read.table("./chart_data_with_redis.txt" , header=TRUE)
withoutRedis <- read.table("./chart_data_without_redis.txt" , header=TRUE)
withRedis $type <- "with Redis"
withoutRedis $type <- "without Redis"
A <- rbind(withRedis, withoutRedis)
# Plot the data
ggplot(data=A, aes(x=url, y=mean, ymin=pmax(mean-sd, 0), ymax=mean+sd, fill=type, linetype=type)) +
geom_line() +
geom_ribbon(alpha=0.5) +
xlab("Url ID") +
ylab("Time (ms)") +
theme(legend.title=element_blank()) +
scale_fill_brewer(palette = "Set1")
Here are the charts, produced by running the bash script with different values of total_ab_requests and parallel_ab_requests (assigned to AB’s n and c parameters respectively):
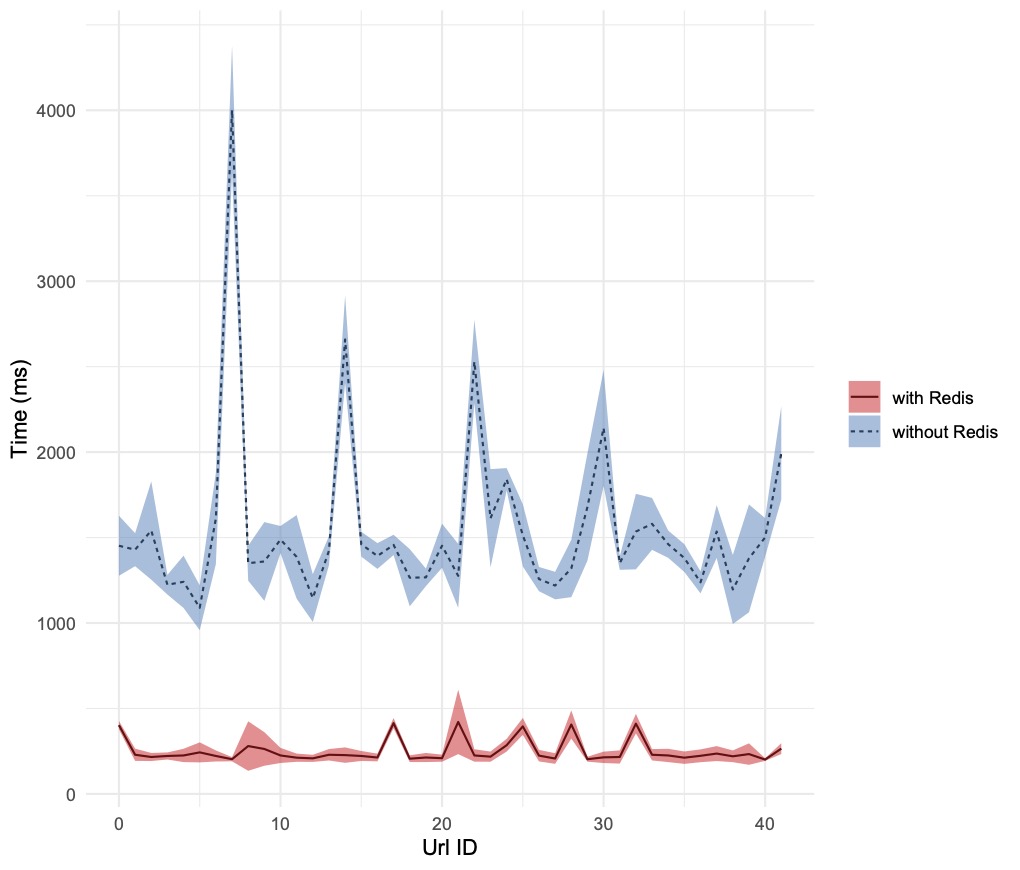
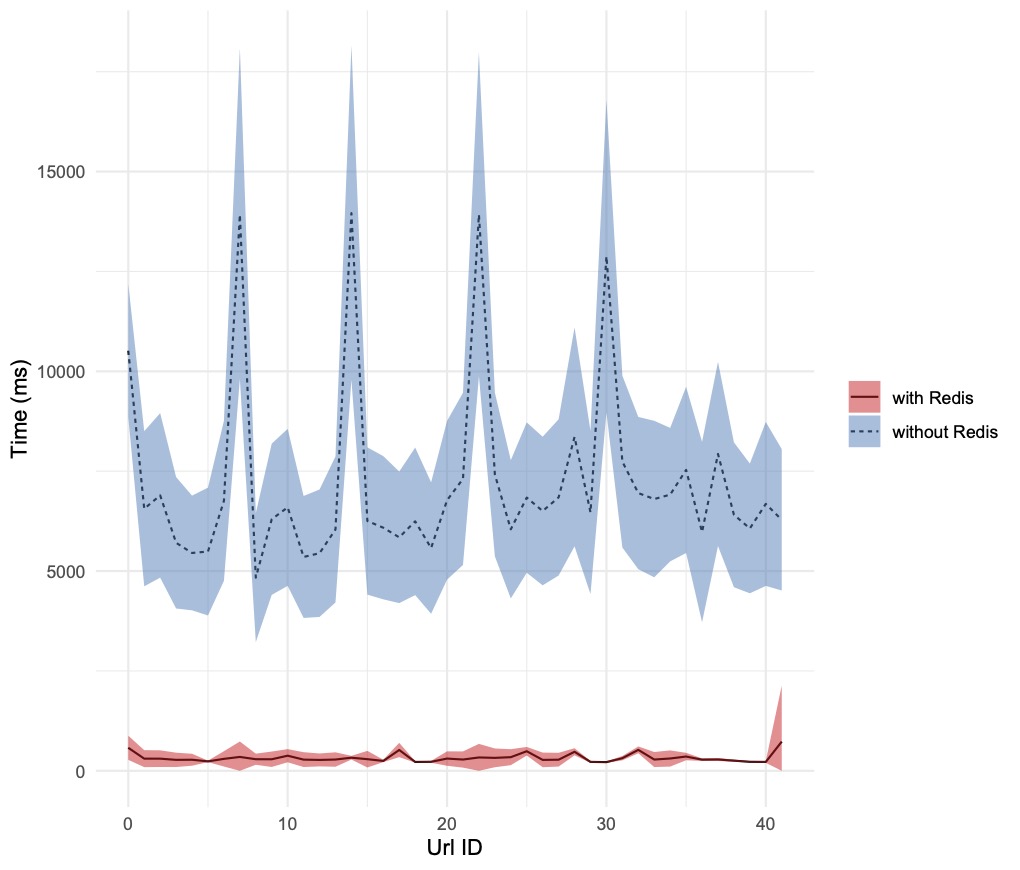
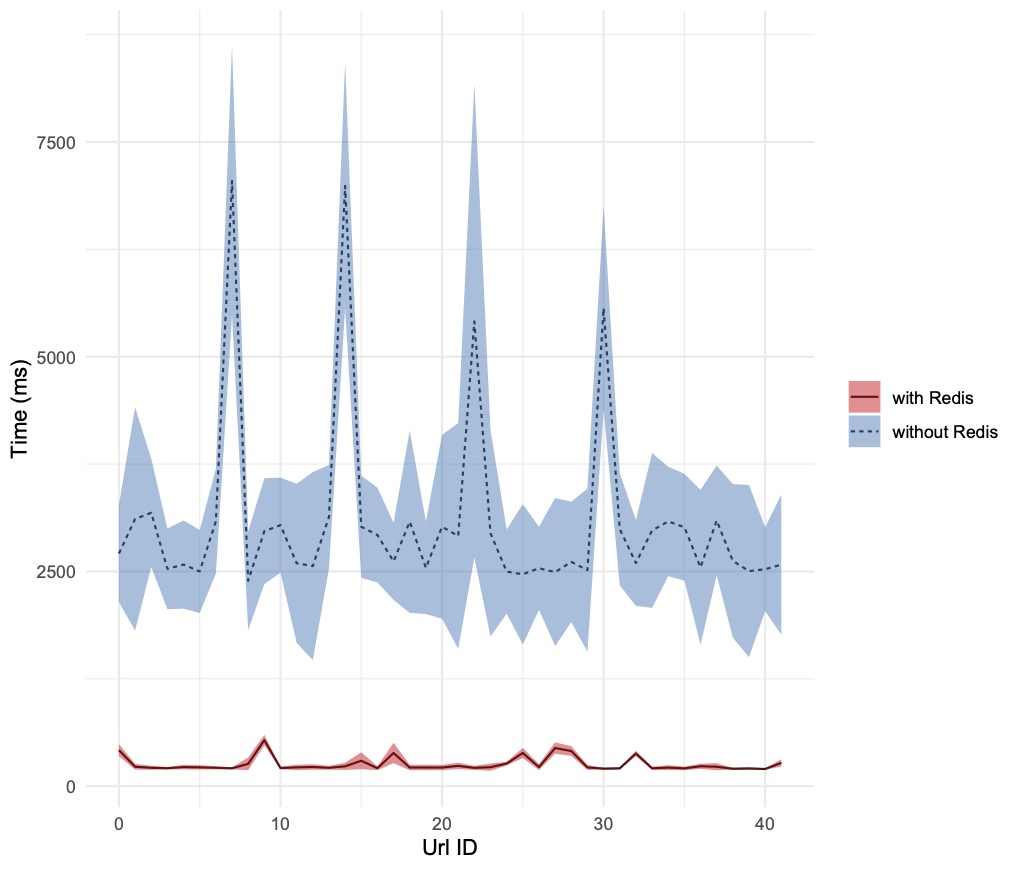
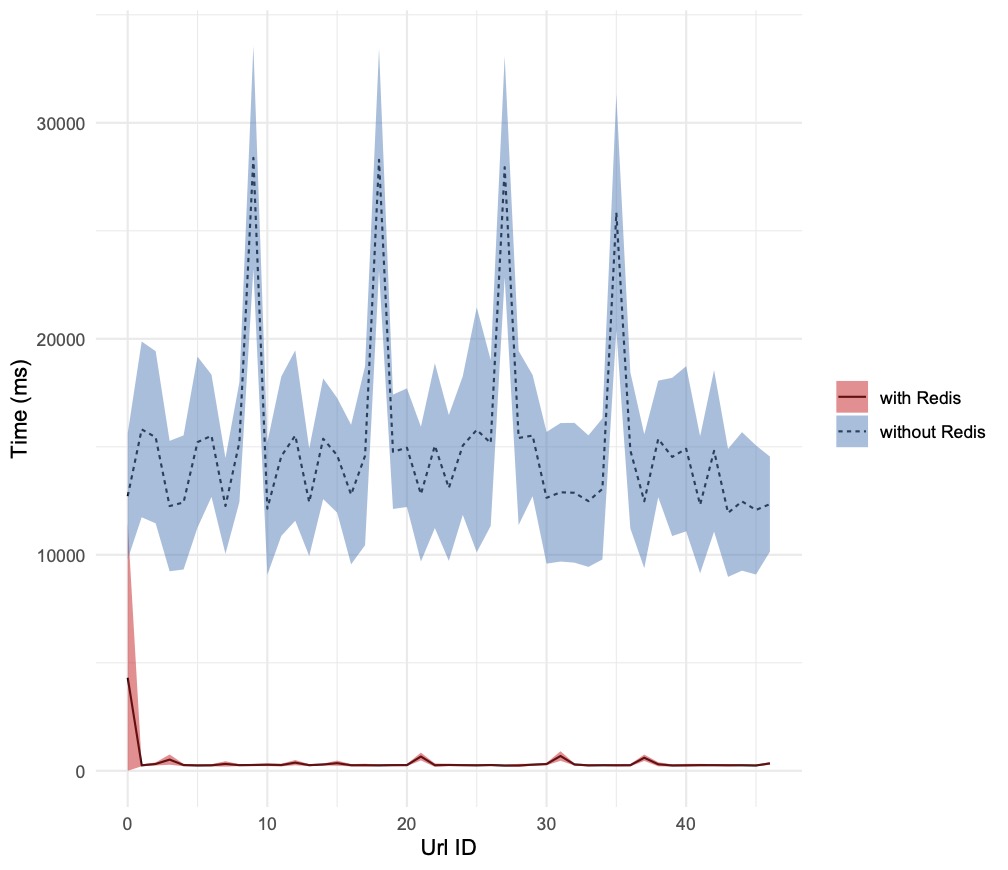
Conclusion
Introducing a cache in the mid-tier layer has reduced the backend latency by a factor ranging from a few times to hundreds of times, depending on the degree of parallelism of the requests. It is worth noting, that with the increase of parallel requests, the standard deviation increases too, reducing the confidence of fulfilling the client requests in a deterministic time frame. In the updates to the Node.js service described previously, Redis was used as a pure key-value store. Further enhancements will be explored, to exploit its capability to accept and manipulate data structures hosted in the values.
