Overview
Apache NiFi is a visual data flow based system which performs data routing, transformation and system mediation logic on data between sources or endpoints.
NiFi was developed originally by the US National Security Agency. It was eventually made open source and released under the Apache Foundation in 2014. This has brought several advantages to the software, creating a large community user base providing support and regular updates.
I have found NiFi to be a particularly useful and rapid solution to apply to problems involving a flow of data from one or more endpoints to another that require some routing and manipulation or validation along the way. Most use cases require little to no coding, as all functionality is provided by the many bundled processors.
Each processor performs a specific given task. It is also possible to write your own processor using Java, or use one of the many written by the NiFi community.
NiFi supports a number of different endpoints including, but not limited to:
File Based, Mongo, Oracle, HDFS, AMQP, JMS, FTP, SFTP, KAFKA, HTTP(S) Rest, AWS S3, AWS SNS, AWS SQS
Apache NiFi can be set up by following the steps for your operating system
After following a few steps and navigating your browser to the default port 8080, you should be presented with the NiFi User Interface, which looks like the following:
This is a canvas where processors can be dragged and dropped and can be connected via flows to other processors and endpoints.
Processors, flows, funnels, ports and groups
Processors
A processor in NiFi performs a discrete task and has one or more inputs or outputs. A freshly installed NiFi comes with a plethora of processors to choose from. We will use a few of these in the simple example flow later on in the post.
Other than inputs and outputs, each processor has settings, schedules and properties, which are unique to each processor and allow changing its behaviour.
An example of a processor may be GetSQL or PostHTTP - Processors are clearly named to describe the exact operation they perform.
Flows
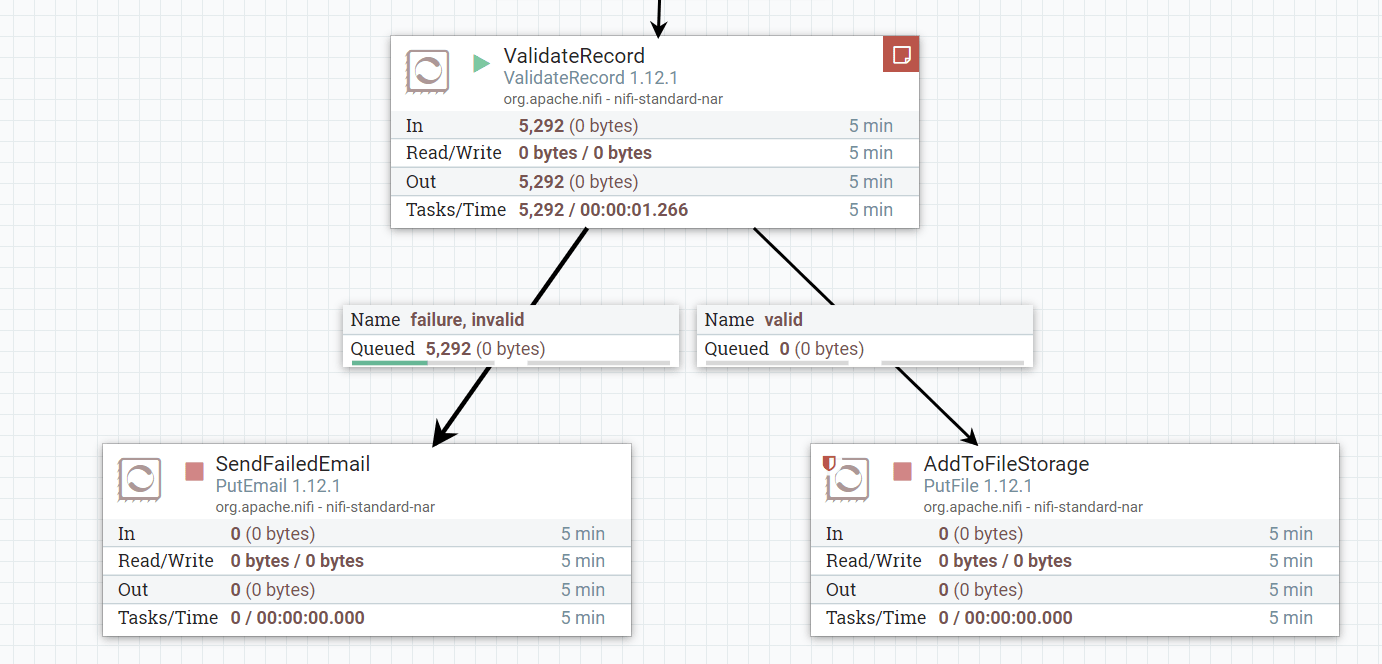
A flow is what connects one processor to another processor, port or funnel, and works in one direction. A flow can be created by dragging a line on a canvas from one object to another.
Each flow has its own internal queue. This queue allows buffering to occur when the downstream process is slower, paused or stopped for whatever reason. Flow queue contents are stored as files on the NiFi server storage, so this needs to be taken into consideration when designing a flow. The queues parameters can be tweaked to allow a finite amount before either deletion, or back-pressure is applied. This post won’t go into either of these advanced topics but I may cover these at a later point.
Usually what happens when we are using a processor, is that each processor has been designed to have one input and more than one output, covering at least one success state and at least one failure state so data can be routed onwards appropriately.
Funnels
A funnel is a conduit aid that allows many flows to converge into a single flow, which helps to ensure a clear layout when lots of flows all have the same fate.
Groups
Groups, or Processor Groups encapsulate a flow of processors into a single object on the canvas, to group any related bits of functionality to tidy away into a named processor group. This processor group can then connect to other processor groups, processors or funnels like a standard processor.
To delve deeper into the processing group, double click to reveal its flow. Processor groups can be used effectively when dealing with large, complex flows that have several discrete functions, utilising a processing group for each function.
Ports
Processor groups use ports to terminate the internal flows and allow them to be accessed outside the process group. A processor group typically has at least one input and one output port.
Flow file Content and Attributes
A NiFi flow transports data from the start to the end of the flow in chunked file content known in NiFi as Flow Files which, by default uses the storage media where NiFi has been installed as a mechanism.
A Flow File consists of Flow File Content and Flow File Attributes. Flow File Content is the entire content of the data of the file, for example the contents of a text file. The Flow File Attributes are metadata attached to each flow file, represented in key value pairs. These attributes are sometimes set by processors themselves, to indicate certain properties or status of a flowfile, but can also be manipulated by the flow designer themselves (This is covered later).
Each flow file can be visually traced on the NiFi UI through the displayed counts as it transits through the flow. We can even look at the content and attributes of a flow file itself when it resides in a flow queue. Right-clicking a flow queue and selecting a flow file presents the file attribute values and content.
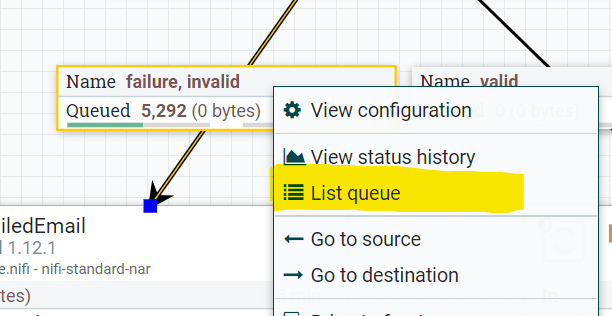
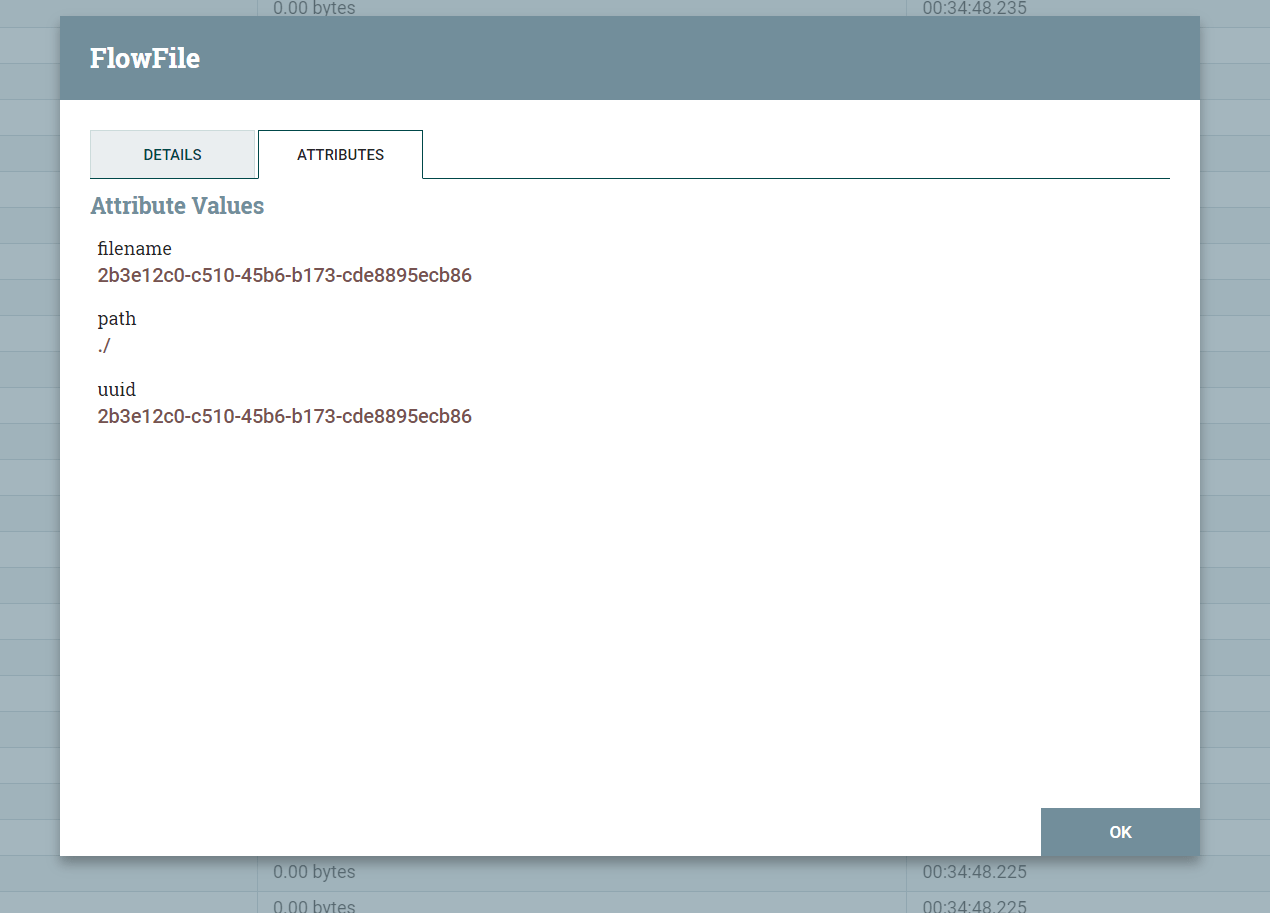
An example flow
Let’s have a go at creating a flow to solve a (very simple) problem. I have a dataset of files in a directory that is populated from some external system. I want these files sorted and placed into different folders based on their content.
These files could really be any format but I have picked files containing JSON file content. This is just random data I have created.
5fa80170fa67ed319b684985.json
{
"_id": "5fa80170fa67ed319b684985",
"index": 0,
"guid": "96a2917d-cab7-4ead-a77e-611b3382202c",
"isActive": false,
"accountType": "savings",
"balance": "$3,234.78",
"name": "Bridgette Bean",
"company": "ACLIMA",
"email": "bridgettebean@example.com",
"phone": "+1 (917) 555-3418",
"address": "136 Moultrie Street, Cornucopia, Kansas, 4294"
}
5fa80170a8ff51d6d8a09a69.json
{
"_id": "5fa80170a8ff51d6d8a09a69",
"index": 1,
"guid": "cdf73b31-4fd1-4484-b69f-b006d62d98fe",
"isActive": false,
"accountType": "current",
"balance": "$1,333.53",
"name": "Erna Sampson",
"company": "MAKINGWAY",
"email": "ernasampson@example.com",
"phone": "+1 (985) 534-2442",
"address": "392 Montague Street, Noblestown, Colorado, 7619"
}
5fa8017059de621e415058c2.json
{
"_id": "5fa8017059de621e415058c2",
"index": 2,
"guid": "58fd7f3f-0404-4d69-88c1-70bc22d167f6",
"isActive": true,
"accountType": "current",
"balance": "$1,227.39",
"name": "Ford McGowan",
"company": "SKINSERVE",
"email": "fordmcgowan@example.com",
"phone": "+1 (932) 403-2763",
"address": "910 Clarendon Road, Rossmore, Delaware, 1990"
}
5fa80170bb4d9e4b5bec5594.json
{
"_id": "5fa80170bb4d9e4b5bec5594",
"index": 3,
"guid": "47feb2fc-b293-4662-8ea0-1d1349eebfb9",
"isActive": true,
"accountType": "savings",
"balance": "$1,801.63",
"name": "Ann Gordon",
"company": "OCEANICA",
"email": "anngordon@example.com",
"phone": "+1 (966) 533-2898",
"address": "363 Monitor Street, Henrietta, Arizona, 1063"
}
I want these files to be placed into two different directories, current and savings based on their accountType.
The first thing we need to do is to add a processor which will read the files in a directory and turn them into flow files. I have used the GetFile processor to do this. Drag the processor symbol in NiFi to add this processor.
Once added to the canvas, set the processor properties to similar values to scan an input directory for JSON files:
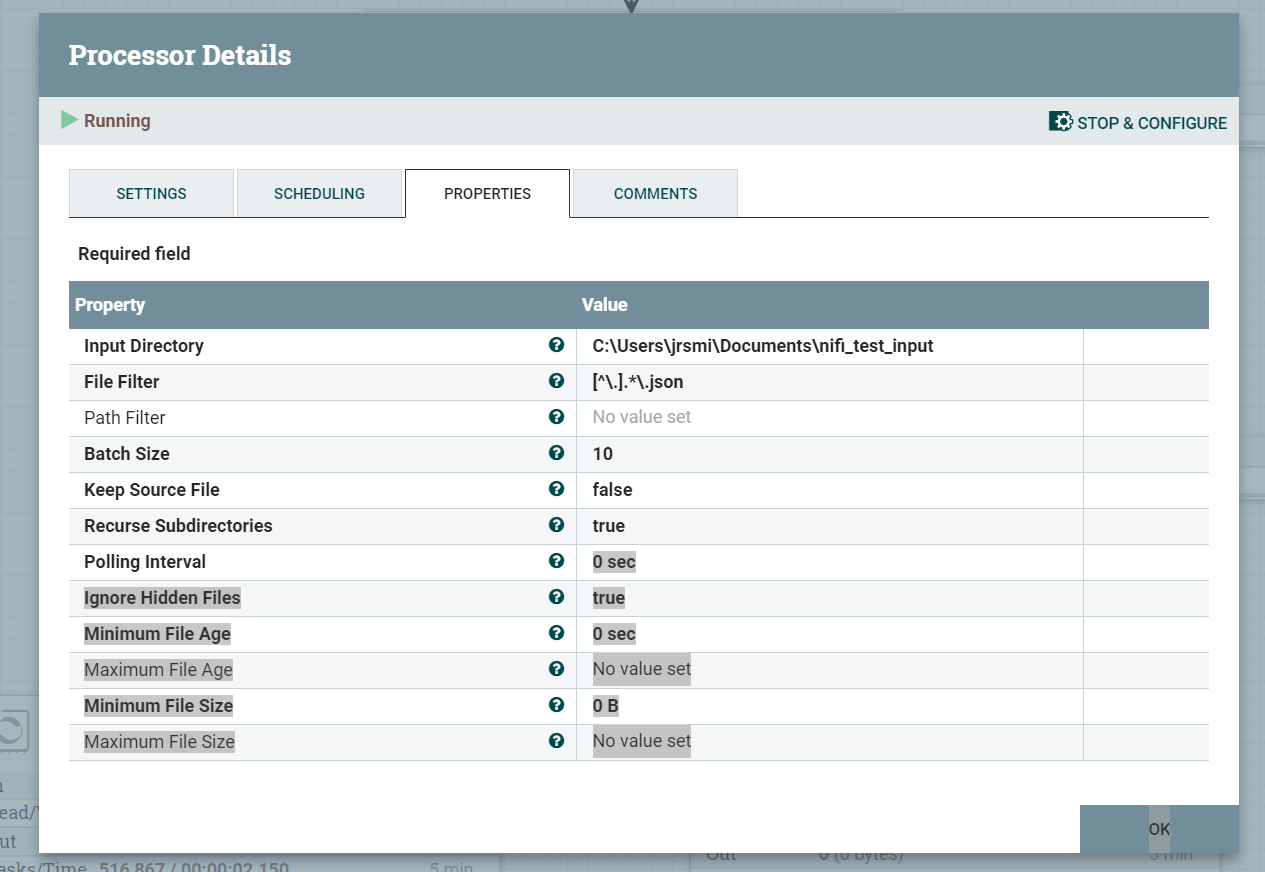
Now that we have the input stage of our flow defined, we need to be able to read the flow file content to be able to decide which direct the files need to be written to. There are a few ways of doing this, but I am using an EvaluateJSONPath processor to read the file content and extract the accountType.
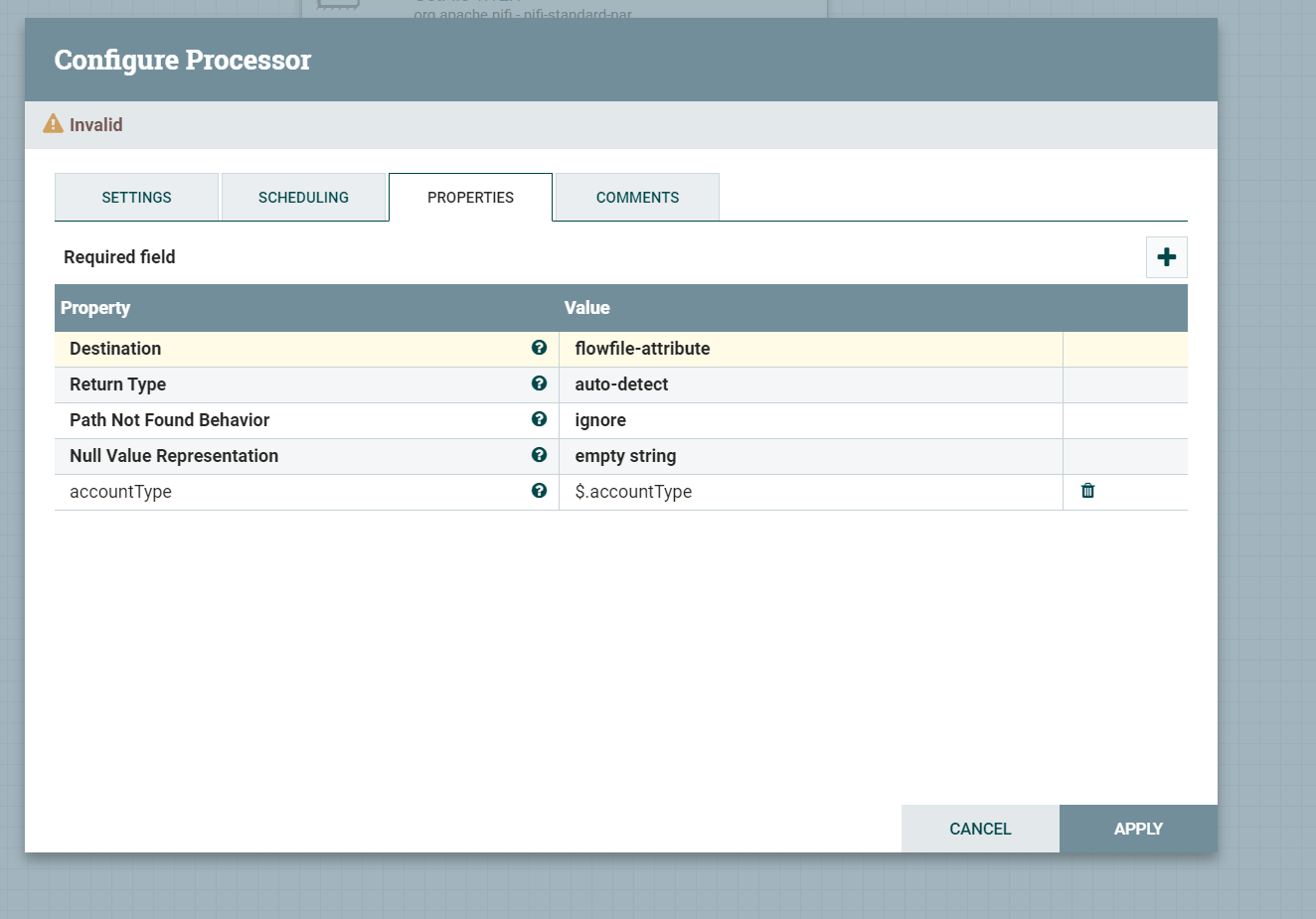
This processor supports addition of custom properties to be able to read custom defined JSON parameters to extract. Add the property name and value above to extract the account Type JSON value from the file into a Flow File Attribute called accountType. The “$.accountType” Is JSONPATH syntax for grabbing a key called accountType from the root JSON node.
Next we need to be able to route our logic based on the accountType flow attribute. To do this we need to use the RouteOnAttributeProcessor. Add this to the canvas and add the following properties:
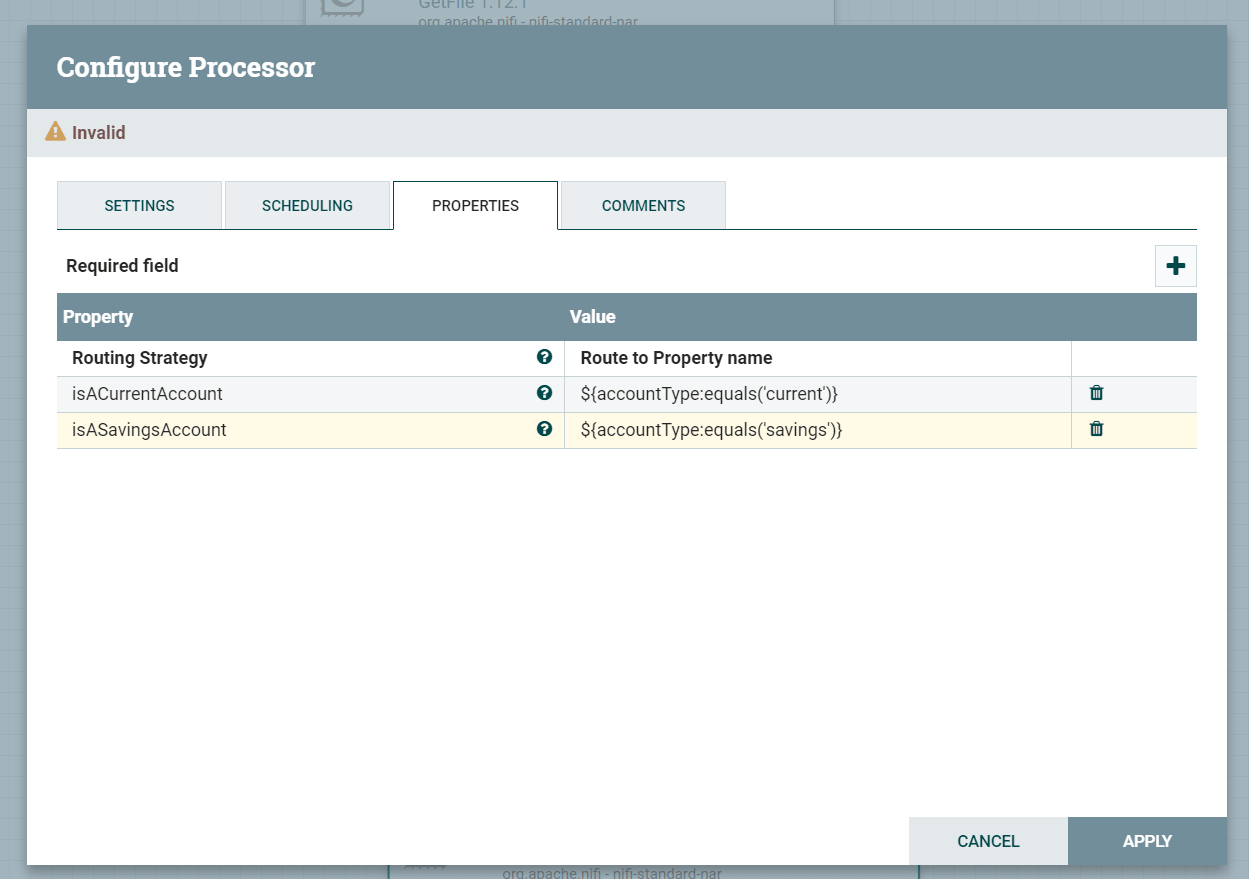
The values for the additional properties make use of something called NiFi expression language, which we will touch upon later, but this is a way of routing to the two different routes based on the setting of accountType.
This routing logic is one of the common design patterns within NiFi. I’ll probably look at some more common design patterns in the next iteration of this post series.
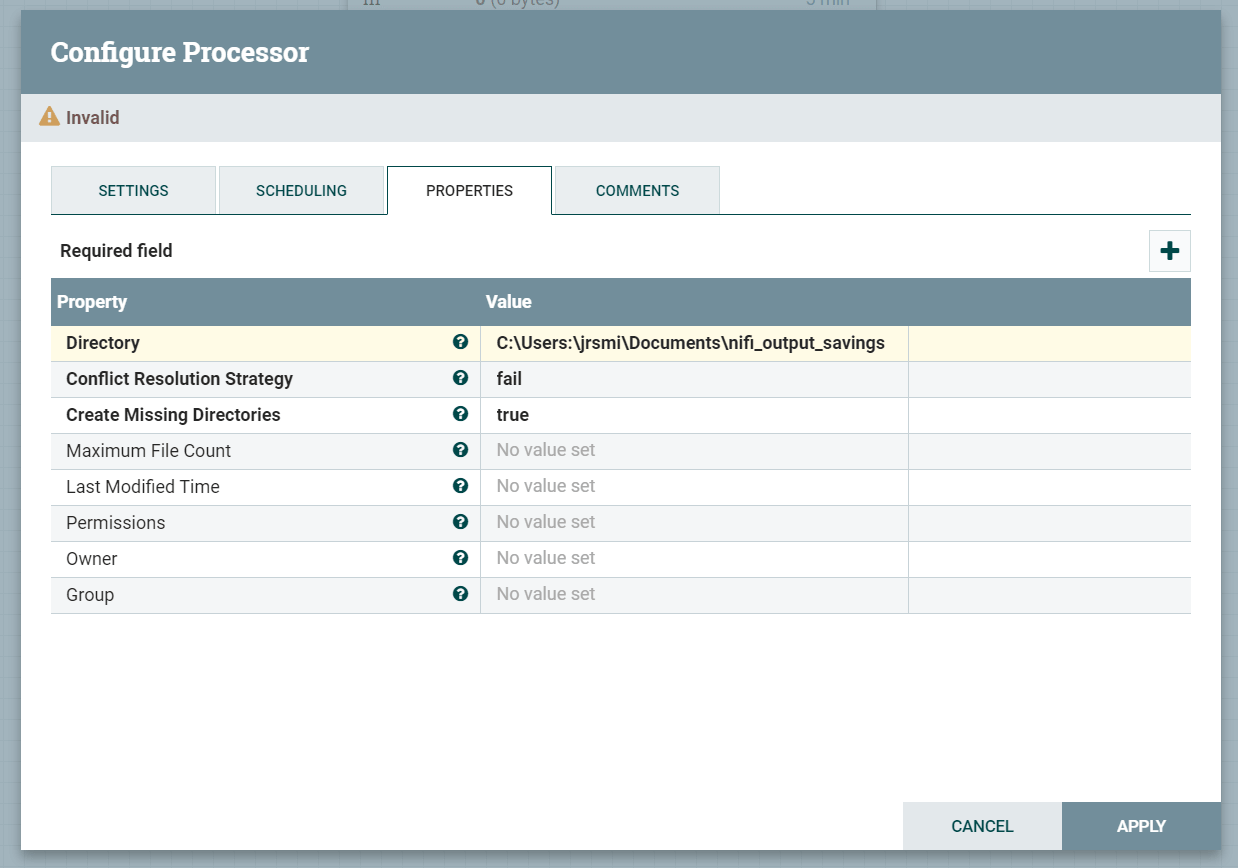
Now that the routing logic is present, we need to add a way of writing the flow files to a folder on the storage. To do this we use a PutFile processor.
Set the properties similar to the below. Note that we will need two of these, one for savings and one for the current account type.
All we need to do now is connect the processors up with flows. Simply drag a line from each processor to the next to create a flow for each success and failure state.
It is good practice to use funnels as a way to extract out terminal flow queues from the flow. E.g. any failures from individual processors and the final success state from the end of the flow.
In the end, your flow should look something like this. If there are no errors a stop symbol will be displayed next to each processor (if you get a warning, hover over the symbol and remediate the issue that is stated).
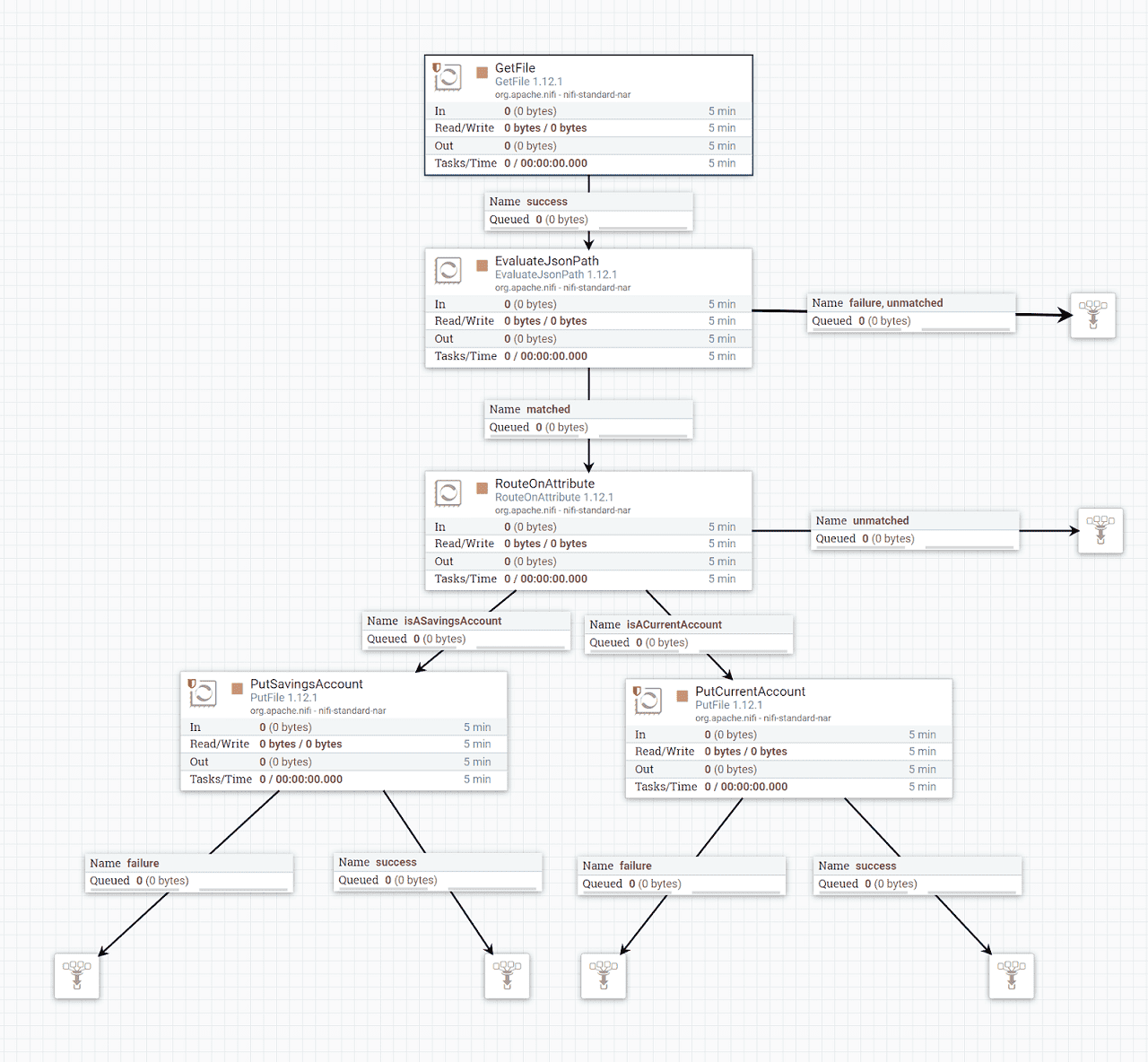
That’s it! A routing system for files in about 10 minutes! To test your flow out you can start each individual processor by right-clicking and selecting start, or by use of a shortcut by right-clicking the canvas and selecting start, which will start all processors in the current canvas.
The flow should route the files to the correct directories as seen in the UI:
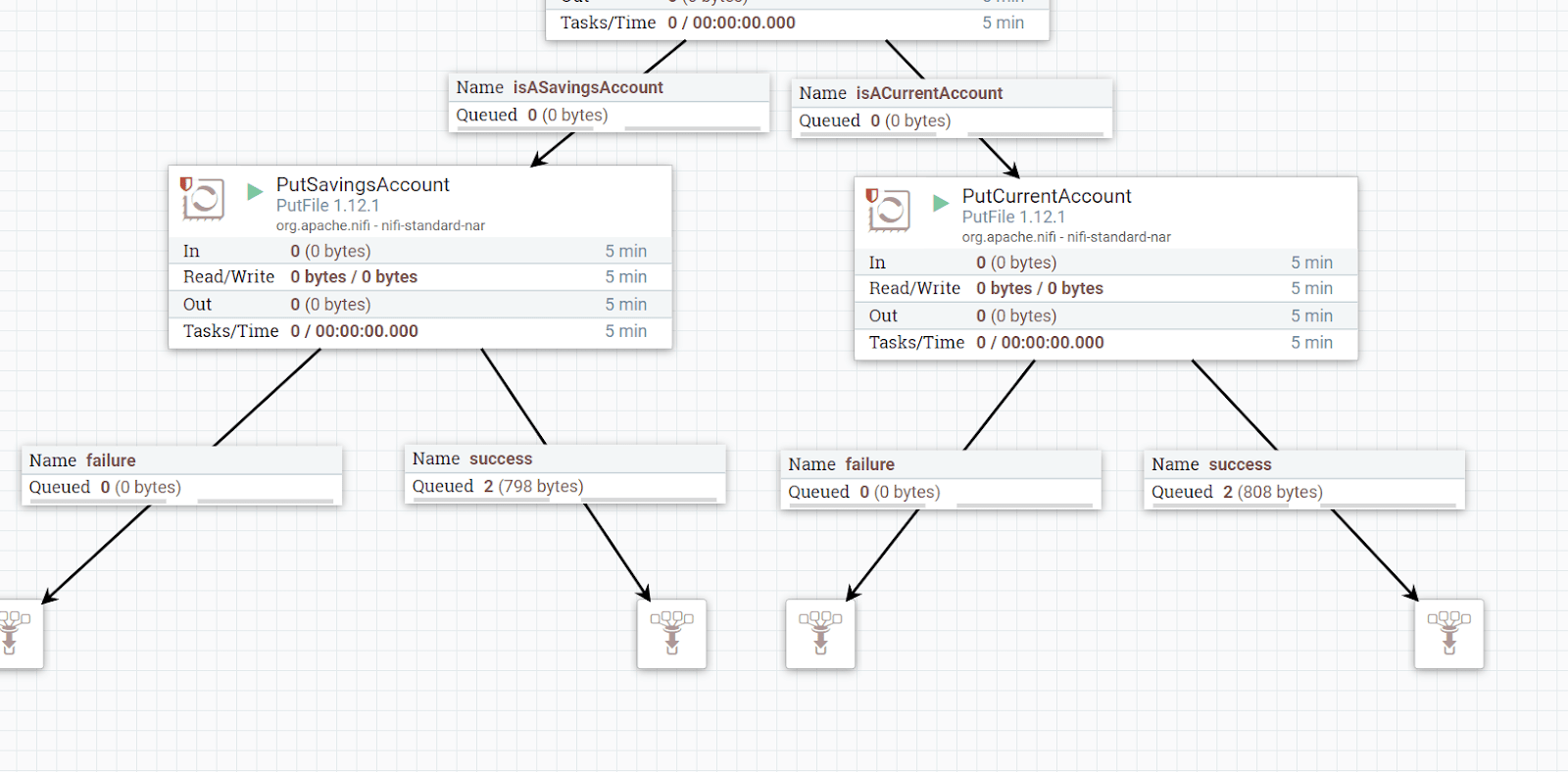
Check the directories to see that the files have been sorted.
In the examples above, we edited the processor properties to add values directly to the processors, such as the file paths, JSON keys to extract et cetera. Is this always the best approach? What if we had a similar file path that is used in more than one processor?
We can use variables as the values for properties and set this variable elsewhere once which will affect all processors that use the variable. Any processor properties that support the NiFi expression language (You can always check by hovering over the question mark icon next to the property).
We are going to change our example flow to abstract out part of the common path we use for our input and output processors. Currently they are set to something like C:\Users\jrsmi\Documents\nifi-test-input,C:\Users\jrsmi\Documents\nifi-output-savings, C:\Users\jrsmi\Documents\nifi-output-current.
We can extract out the base path as it is the same for all of the processors.
Right-click on the canvas and select variables. Add a new variable basePath and set it similar to the following:
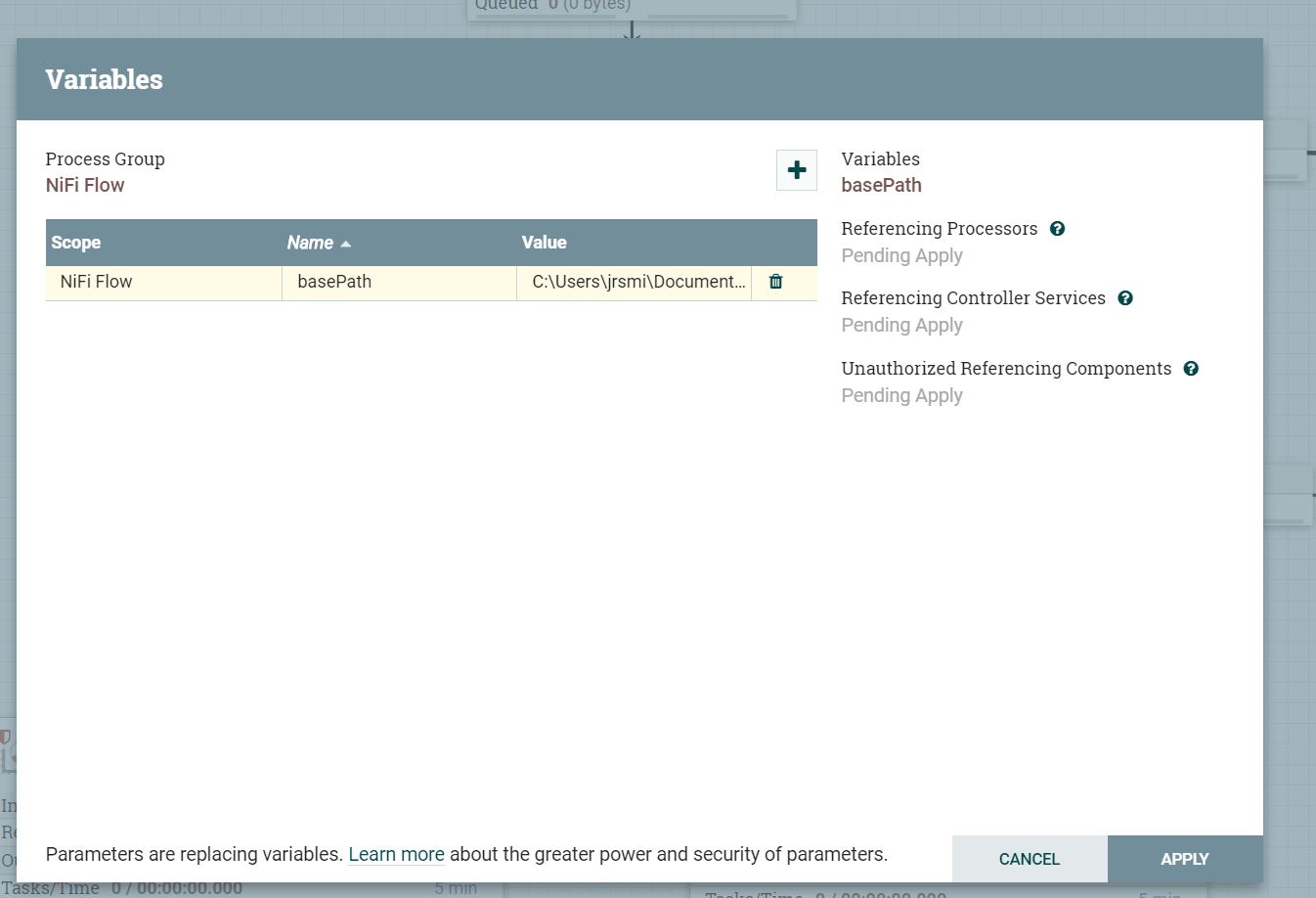
Now go into the GetFile and PutFile processors and replace the preceding part of the filepath string with the new variable(note that you will need to stop the processor first before making any changes)
All variables in NiFi are represented using the syntax ${variableName}. The processor properties should look like the following:
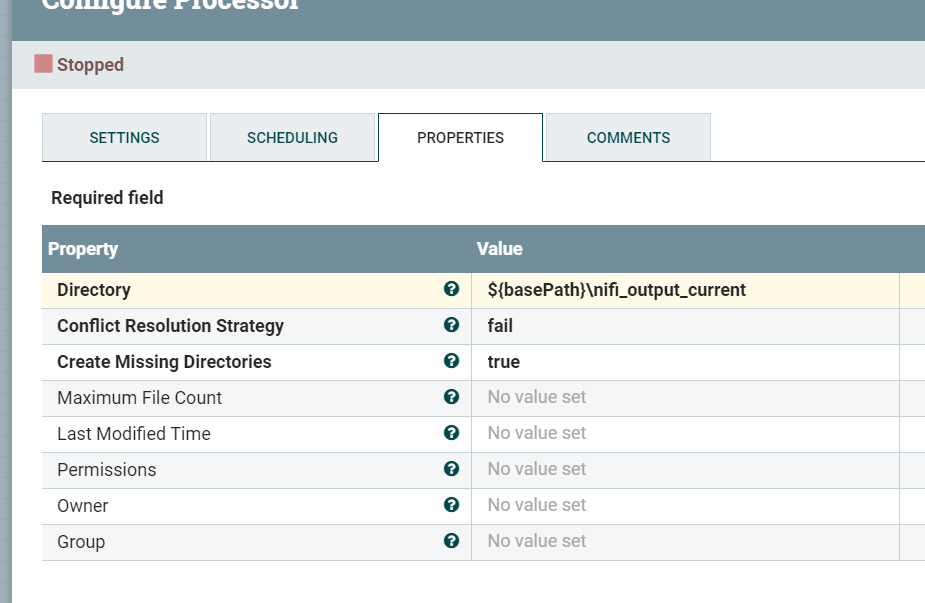
That’s it! Try playing your NiFi flow again and check it still works.
Setting and updating flow based attributes, UpdateAttribute Processor
Previously we talked about processors automatically setting Flow File attributes based on a processing operation performed on a Flow File. Flow file attributes can also be set manually by using the UpdateAttribute Processor as part of a flow. This is useful in a number of cases, one of which we can demonstrate by selectively setting the filename in our example flow based on which account route the flow goes down.
Add an UpdateAttribute processor and add a new filename property to the process as per below.
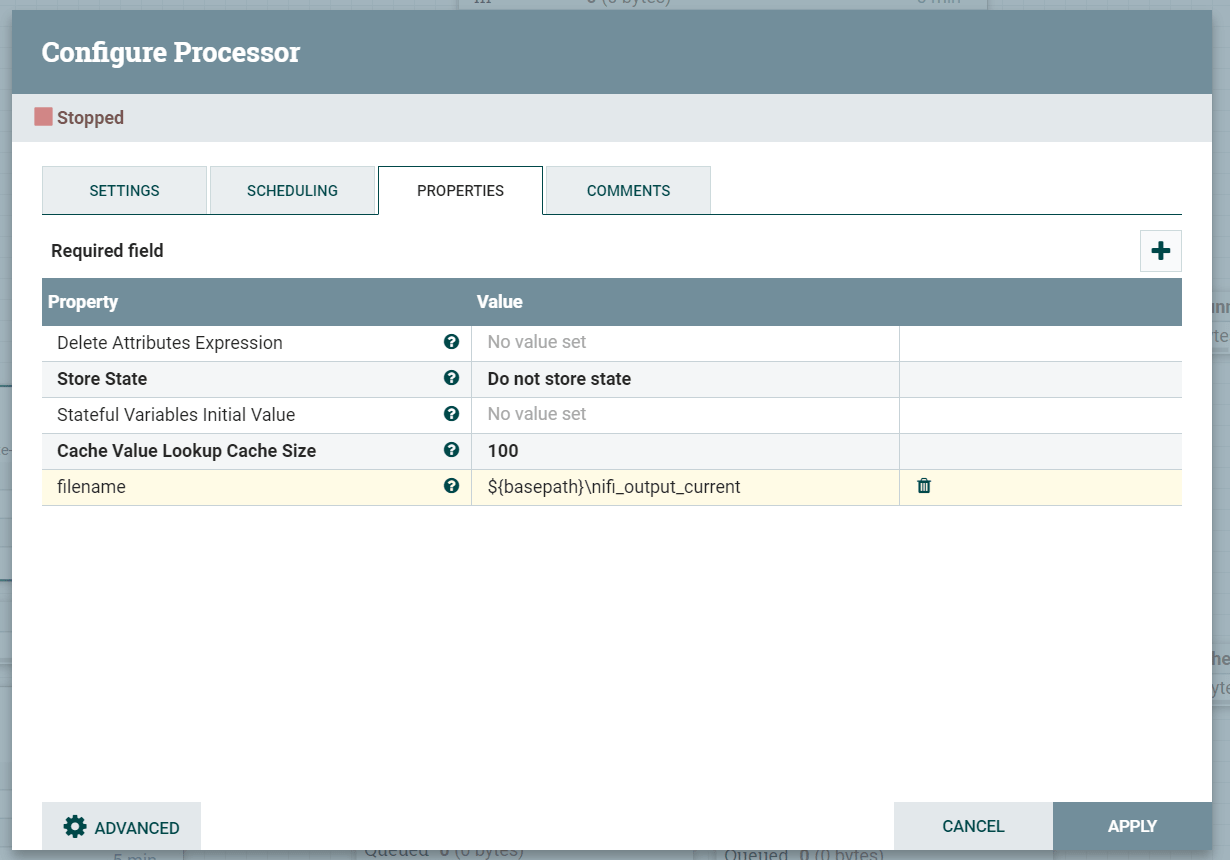
Now add this processor in between the RouteOnAttribute and Putfile processor for the current account.
Change the output directory property of the PutFile processor to simply use ${filename}. The flow will look like the below diagram.
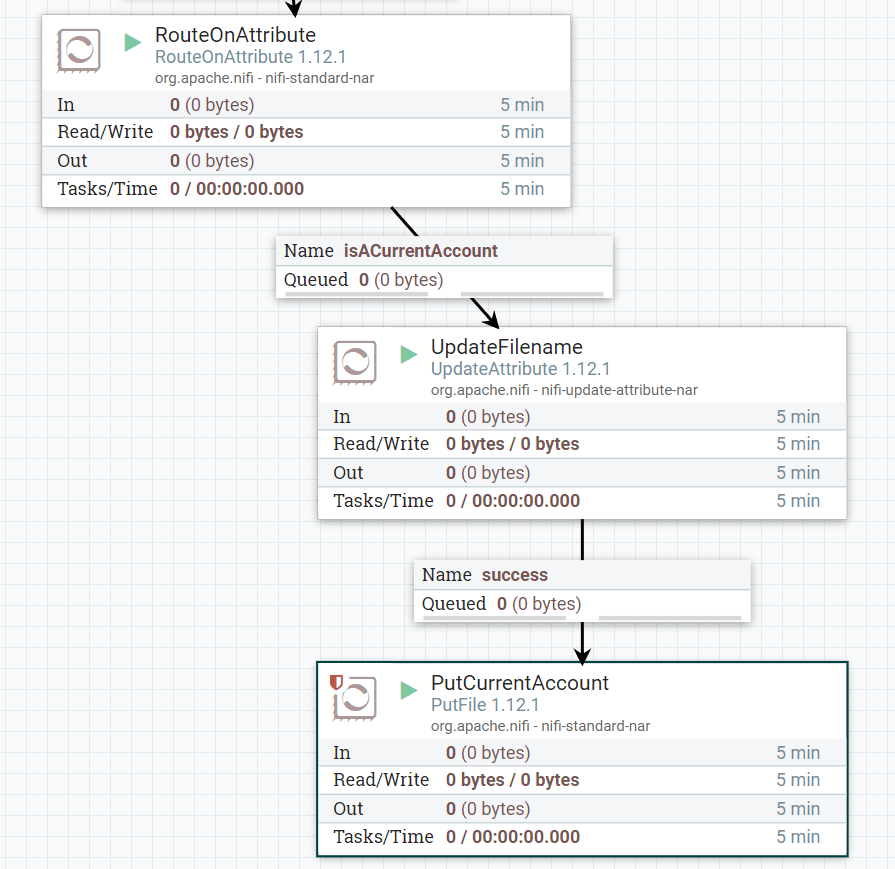 You have now demonstrated the use of setting flow attributes dynamically.
You have now demonstrated the use of setting flow attributes dynamically.
This can be very powerful with certain flow logic, particularly when determining where a flow file originates from and what should happen to it.
NiFi Expression Language
The NiFI expression language is a powerful way of adding logic and manipulation into processors in a pseudocode fashion. We have used the NiFi Expression Language a few times already to perform variable substitution and check whether an attribute contains a certain value to perform routing.
NiFi expression language is primarily written in the values of processor properties. The NiFi expression guide can be found at NiFi Expression Language Guide or by right-clicking any processor and selecting the “Usage” option.
A few common examples of function that can be performed using the NiFi Expression Language are: String Manipulation, Maths Operations, If Then Else…. DateTime operations and encoding. Some of these functions will be explored in the next parts of this guide.
Best Practices
This is by no means a list of strict commands you must follow, as your use cases may be different and warrant a slightly different approach, but more of a guidance to ensure some good practices are met when designing flows.
I will be adding to this section with more good practices and guidelines to follow. Please feel free to suggest any good practices you follow.
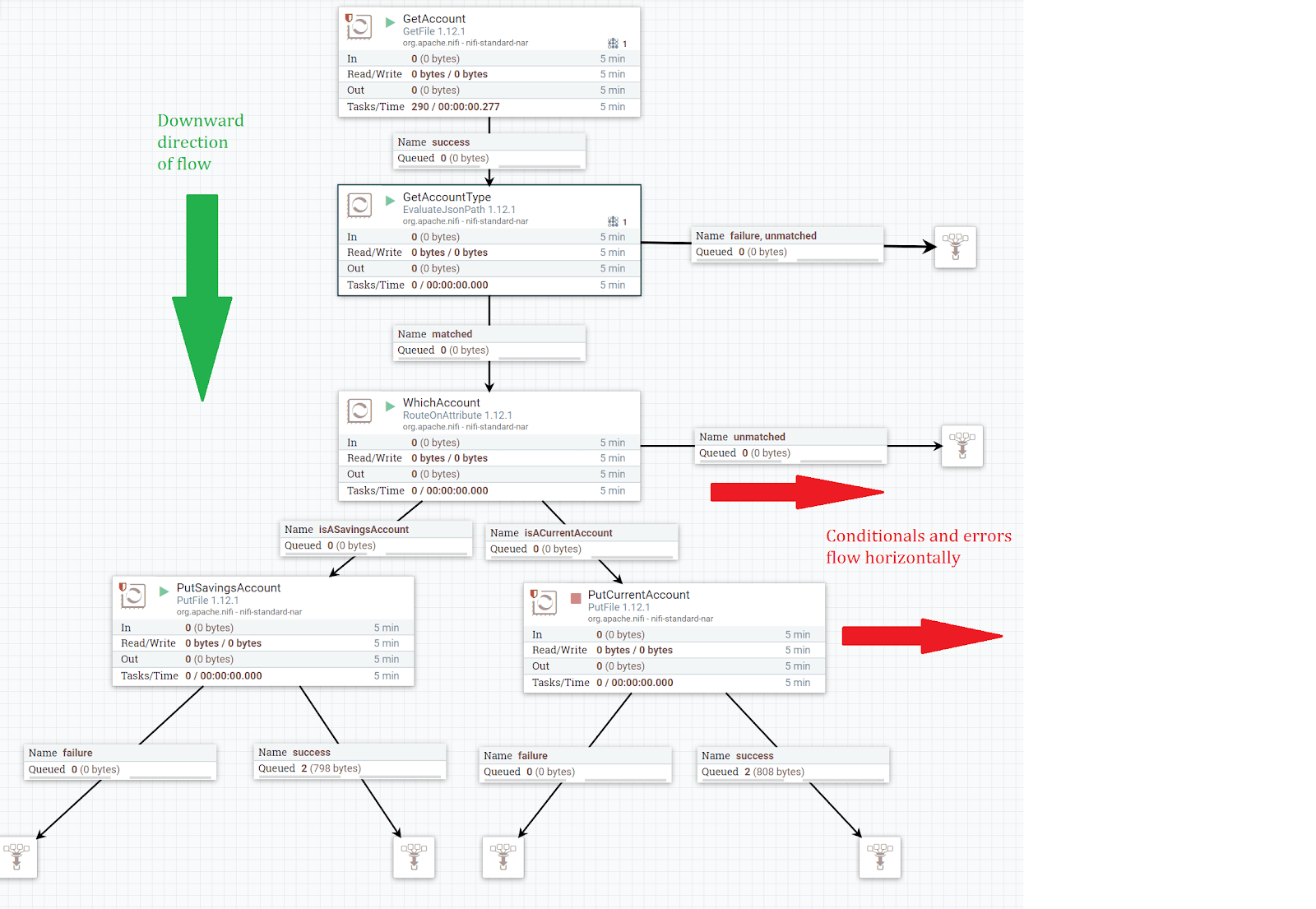
Layout
-
The layout of a flow should be modelled on gravity. Gravity pulls objects down towards the earth and flow files should generally follow this approach where successful flow files are pulled down towards the bottom.
-
When a logic decision is made, for example route on attribute or some other place the flow splits, the flow should move horizontally, right or left, before continuing on its downward path as seen in the example below.
-
Error handling and failures should also be handled horizontally where possible, at the same level as the processor which produces the failure.
Naming
- All processors should be renamed from their defaults to give a good description of what they are doing. E.g.
RouteOnAttributerenamed toWhichAccount,PutFiletoPutSavingsAccountand be unique from any other processor. This doesn’t just help visually to distinguish the processor, but also when reading the log file to pinpoint an error when something goes wrong.
Error Handling
I have seen multiple ways of handling flow file errors - some good, some bad. Here are some of my recommendations to follow.
- Avoid auto-terminating flows, always add queues for each flow condition so error conditions can be spotted quickly
- Don’t be tempted to group flow conditions together like in the diagram above with failure and unmatched (this was done for simplicity) as it becomes difficult to distinguish which flow condition resulted in the file on that queue
- For a similar reason, do not be tempted to do what I see often and route all failures from processors into a single failure point. Users of the flow should be able to see by the use of queue counts how many files have resulted from each processor flow status.
Processor Groups
- Utilise these wherever possible to group common functionality. For example we could make our example flow contain Input, Sorting and Output processing groups, which would encapsulate the related logic
- Don’t make processing groups any more than two levels deep, it becomes very easy to get lost and a chore to drill down into N levels of abstraction
Use of Variables and Scoping
- Use variables when and wherever possible to control all flow parameters from a single place. The top level is usually a good place for variables that have an effect on all processors and processor groups, otherwise it is good to have variables at the processor group level. For example when you have two output stages that will have different variable values.
In Part 2, we will look at securing the NiFi Control UI using certificates and access control roles and groups, posting and reading from REST endpoints, the NiFi registry, additional design patterns, managing source control changes to the NiFi flows and Clustering/High Availability.